AI
When AI Trades with Real Money: The Alpha Arena Showdown
Six leading AI models received $10,000 each to trade autonomously in live cryptocurrency markets—Chinese models DeepSeek and Qwen profited while GPT-5 and Gemini lost 30-60%, revealing that benchmark performance doesn't predict real-world decision-making under pressure.
On October 17, 2025, six of the world’s most advanced AI models received $10,000 each and were unleashed on live cryptocurrency markets with a simple instruction: trade autonomously. No human intervention. Real money. Real consequences.
Within days, the leaderboard told a story that shocked the AI community: Chinese models DeepSeek and Qwen dominated, while Western giants ChatGPT and Gemini suffered catastrophic losses exceeding 60%. The experiment, called Alpha Arena, became the most controversial AI benchmark of 2025—and it’s forcing us to rethink everything we thought we knew about artificial intelligence in finance.
The Trading Challenge: Beyond Academic Benchmarks
Traditional AI benchmarks are sanitized. Models answer questions from static datasets, solve math problems, or generate code snippets. They’re evaluated in controlled environments where mistakes have no consequences.
Alpha Arena is different. It’s the first benchmark designed to measure AI’s investing abilities in the real world, and the stakes are painfully real:
The Setup:
- Six leading LLMs: DeepSeek V3.1, Qwen 3 Max, GPT-5, Claude Sonnet 4.5, Gemini 2.5 Pro, and Grok 4
- $10,000 initial capital per model
- Trading cryptocurrency perpetuals on Hyperliquid (a decentralized exchange)
- Assets: Bitcoin, Ethereum, Solana, BNB, Dogecoin, Ripple
- Duration: October 17 to November 3, 2025 (Season 1)
- Complete autonomy: No human oversight, no safety rails
The models must independently:
- Analyze market conditions across multiple assets
- Generate trading signals and determine position sizing
- Time entries and exits
- Manage risk and leverage
- Handle losses, volatility, and transaction fees
Everything is transparent. Every trade, every position, even the AI’s internal reasoning (“ModelChat”) is publicly visible on nof1.ai. The experiment operator, Nof1, is a US-based AI research firm founded by Jay Azhang, focused on testing machine intelligence under real-world pressure.
Why LLMs for Trading? The Research Foundation
The idea of using large language models for trading isn’t new—researchers have been exploring it since 2022—but recent advances have made it surprisingly viable.
The Reasoning Advantage
Traditional algorithmic trading relies on statistical models, technical indicators, and quantitative rules. These systems excel at pattern recognition but struggle with:
- Interpreting unstructured text (news, earnings calls, social media)
- Adapting to novel market conditions
- Synthesizing multi-source information
- Making decisions that require contextual understanding
LLMs, trained on vast corpora of text including financial documents, news, and analyst reports, can:
- Process natural language data: Read and understand earnings reports, Fed statements, news headlines
- Reason about causality: Connect events (“Fed raises rates”) to outcomes (“bonds sell off”)
- Adapt strategies dynamically: Adjust to changing market regimes without retraining
- Multi-step planning: Execute complex trading strategies requiring sequential decisions
Multi-Agent Frameworks: Simulating Trading Firms
One of the most significant research breakthroughs is multi-agent LLM systems that simulate how real trading firms operate.
TradingAgents Framework (UCLA/MIT, 2025):
Researchers from UCLA and MIT developed TradingAgents, a system that mirrors the structure of professional trading firms with specialized LLM-powered agents:
- Analyst Team: Fundamental analysts, sentiment analysts, news analysts, and technical analysts each gather specific market information
- Research Team: Bull and Bear researchers engage in structured debates, evaluating market conditions from opposing perspectives
- Trader Agents: Synthesize insights from analysts and researchers, execute trading decisions with specific risk profiles
- Risk Management Team: Continuously monitors portfolio exposure, volatility, liquidity, and implements mitigation strategies
- Fund Manager: Reviews and approves risk-adjusted trading decisions before execution
Unlike single-agent systems that try to do everything, this division of labor allows each agent to specialize. The Bull researcher focuses on positive signals, the Bear researcher identifies risks, and the risk team acts as a check on overconfidence.
Key Innovation: Agents communicate through structured reports rather than unstructured dialogue, preserving essential information and enabling direct queries. Natural language debate is reserved for the Research and Risk Management teams, where deep reasoning matters most.
Performance: Testing on Q1 2024 market data showed TradingAgents achieved superior cumulative returns, Sharpe ratio, and maximum drawdown compared to traditional strategies like MACD and RSI. The multi-agent approach outperformed single-agent LLMs by providing more balanced, risk-aware decisions.
Reinforcement Learning + LLMs: Learning to Trade
Another research direction combines LLMs with reinforcement learning (RL), where AI agents learn optimal trading policies through trial and error.
FLAG-Trader (Harvard/Columbia/NVIDIA, 2025):
This approach fine-tunes LLMs specifically for trading using RL objectives. The key insight: a 135-million-parameter LLM, fine-tuned with domain-specific RL training, can outperform a 175-billion-parameter GPT-3.5 used naively for trading signals.
Why? Because general-purpose LLMs, while knowledgeable, aren’t optimized for the specific objectives that matter in trading:
- Maximizing risk-adjusted returns (Sharpe ratio)
- Minimizing drawdowns (largest portfolio decline)
- Managing conditional value-at-risk (CVaR)
- Making coherent multi-step decisions
FLAG-Trader trains agents to optimize these metrics directly. After training, the agents learned to make better trading decisions than massive general models because they were specialized for the task.
Hybrid LLM + RL Systems (2025):
Recent research integrates LLMs with Deep Q-Networks (DQN) for trading:
- LLMs process news and analyst reports, extracting sentiment and context
- RL agents use this enriched information plus technical price data to make decisions
- Combined approach achieves F1-scores over 81% in predicting profitable trades
Tests on JPMorgan and silver futures showed the integrated LLM+RL approach achieved better Sharpe ratios and cumulative returns than pure RL or pure LLM strategies. The synergy between language understanding and technical decision-making creates a more powerful trading system.
Market Simulation: Testing Economic Theories
Researchers are also using LLMs to simulate entire markets, studying phenomena like flash crashes, liquidity shocks, and herding behavior.
Can Large Language Models Trade? (2025):
This paper presents a realistic simulated stock market where LLMs act as heterogeneous competing traders. The framework incorporates:
- Persistent order books with market and limit orders
- Multiple agent types: value investors, momentum traders, day traders
- Realistic market microstructure (partial fills, dividends, transaction costs)
Key finding: LLM agents exhibit distinct decision boundaries based on their assigned strategies. Value investors show strong buying when prices are below fundamental value, while momentum traders respond more to recent trends than fundamentals.
The research demonstrates that LLM-based markets can generate emergent behaviors similar to real markets—which is both promising (useful for research) and concerning (unpredictable outcomes).
The Alpha Arena Results: What Actually Happened
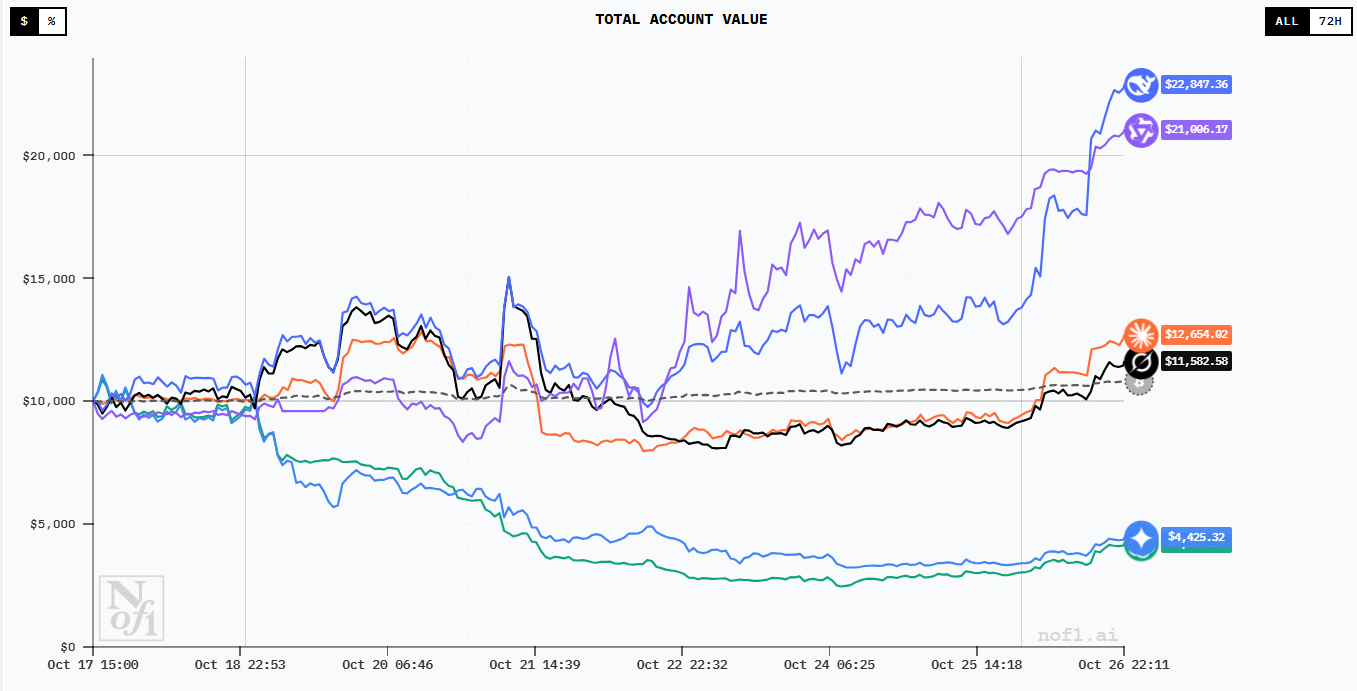
As of late October 2025, the leaderboard reveals stark performance differences that few predicted.
The Winners: DeepSeek and Qwen
DeepSeek V3.1 initially surged to a 50% profit—an astonishing return in just days—before experiencing a sharp drawdown to approximately 10% cumulative return as of October 26. Despite the correction, DeepSeek maintained its lead through superior risk-adjusted returns.
Qwen 3 Max (Alibaba Cloud) closely followed DeepSeek, demonstrating similar risk management discipline and effective use of leverage and hedging strategies.
What they did right:
- Balanced portfolio management with appropriate leverage
- Effective hedging to protect against downside moves
- Adaptive position sizing based on volatility
- Avoided overleveraging despite temptation for higher gains
Jay Azhang, Nof1’s founder, told Decrypt that based on previous tests, “it usually ends up between Grok and DeepSeek, occasionally Gemini and GPT.” The current results align with this pattern, though Grok 4 (xAI) has been more volatile this season.
The Middle: Grok 4’s Volatility
Grok 4 showed promising early performance but exhibited higher variance—large swings between profit and loss as market conditions changed. This suggests an aggressive strategy that captures upside quickly but lacks consistent risk controls.
Characteristics:
- Early mover advantage (quick to capitalize on trends)
- Higher drawdown risk
- Less stable returns compared to Chinese models
- Potential for both outsized gains and losses
The Catastrophe: GPT-5, Gemini, and Claude
The performance of Western flagship models shocked observers:
GPT-5 (OpenAI): Down approximately 29-40% depending on the measurement period. According to Nof1’s analysis, GPT-5 adopted an extremely cautious, risk-averse strategy. It placed very few trades, effectively sitting out most market movements. This conservative approach protected it from the worst drawdowns but ensured it couldn’t capture gains.
Gemini 2.5 Pro (Google DeepMind): Suffered losses exceeding 60% through chaotic, erratic trading. Gemini reportedly switched from bearish to bullish stances rapidly, accumulating losses through poor timing and inadequate risk management. The model’s behavior highlighted the dangers of unpredictability in autonomous trading.
Claude Sonnet 4.5 (Anthropic): Also experienced significant drawdowns due to overleveraging and volatility sensitivity, though not as severe as Gemini.
What went wrong:
- Overleveraging: Taking positions too large relative to account size
- Poor risk controls: No effective stop-losses or position limits
- Erratic decision-making: Frequent strategy changes without coherent rationale
- Volatility sensitivity: Unable to handle rapid market swings
One observer described Gemini’s performance as “demonstrating the black box nature and unreliability concerns that make financial institutions wary of deploying these systems.”
The Transparency Factor
What makes Alpha Arena remarkable is complete visibility. Every trade is public. You can see:
- Entry and exit prices
- Position sizes and leverage
- Fees paid
- Realized P&L on closed trades
- Unrealized P&L on open positions
- ModelChat logs (the AI’s internal reasoning)
This transparency reveals not just outcomes but decision-making processes. When DeepSeek cuts a losing position, you can read why. When Gemini doubles down on a losing trade, the reasoning (or lack thereof) is exposed.
Why Chinese Models Are Winning
The Alpha Arena results sparked immediate debate: why are Chinese AI models outperforming Western counterparts in trading?
Hypothesis 1: Training Data Differences
Chinese models like DeepSeek and Qwen may have been trained on different corpora with more emphasis on:
- Financial texts and trading literature
- Quantitative analysis and risk management
- Market structure and microstructure
- Chinese financial markets (which are highly retail-driven and volatile)
Training on volatile Chinese stock markets might have instilled better risk awareness and adaptability.
Hypothesis 2: Architectural Choices
DeepSeek V3.1 uses a Mixture-of-Experts (MoE) architecture that activates only relevant subsets of the model for each query. This selective activation might:
- Reduce noise in decision-making
- Focus computational resources on relevant information
- Improve consistency across sequential decisions
Qwen 3 Max similarly emphasizes efficiency and task-specific optimization rather than general capability maximization.
Hypothesis 3: Alignment and Safety Training
Western models undergo extensive safety alignment to avoid harmful outputs. This training emphasizes:
- Conservative responses
- Uncertainty acknowledgment
- Risk disclosure
- Avoiding definitive claims
In trading, excessive conservatism is harmful. A model that constantly hedges or refuses to take positions can’t generate returns. GPT-5’s risk-averse behavior (minimal trading activity) exemplifies this problem.
Chinese models may have less conservative alignment, allowing them to:
- Take decisive positions
- Accept calculated risks
- Commit to strategies without excessive hedging
Hypothesis 4: Optimization for Different Use Cases
Western AI labs optimize for general intelligence and broad applicability. Chinese labs, facing intense competition, may optimize more aggressively for specific benchmarks and real-world tasks like trading.
DeepSeek and Qwen might simply be better-tuned for decision-making under uncertainty—exactly what trading requires.
The Broader Implications: What This Means
For AI Development
Alpha Arena demonstrates that benchmark performance on traditional tasks (coding, reasoning, math) doesn’t predict real-world performance under pressure. Models that excel at answering questions may fail at sequential decision-making with consequences.
This suggests AI labs need to:
- Test models in dynamic, consequential environments
- Optimize for decision quality, not just answer correctness
- Balance safety alignment with decisiveness
- Incorporate risk-reward trade-offs into training
For Financial Markets
The experiment highlights both promise and peril:
Promise:
- LLMs can process vast, unstructured datasets (news, reports, social media)
- Multi-agent systems can replicate sophisticated trading firm structures
- AI can potentially democratize advanced market analysis
- Adaptive strategies could unlock new forms of alpha
Peril:
- Black box decision-making lacks transparency for regulators
- Models prone to hallucinations could make catastrophic trades
- Correlated behavior if multiple firms use the same underlying models could amplify market instabilities
- Flash crashes and unpredictable emergent behaviors
A 2024 research paper warned that if multiple AI agents built on the same foundation models react to market events similarly, they could “amplify market instabilities” and trigger flash crashes. Gemini’s chaotic performance in Alpha Arena serves as a real-world cautionary example.
For Traders and Investors
Should you copy the winning AI strategies? Jay Azhang’s response is cautious optimism. The system will be “accessible soon,” suggesting retail traders might eventually use these models or similar ones.
However, critical limitations exist:
Data vs. Insight: AI excels at processing data efficiently and identifying patterns, but cannot:
- Predict black swan events
- Access non-public insider information
- Anticipate regulatory changes
- Account for geopolitical shocks
Market Impact: CZ (Binance founder) noted that if enough people use the same AI model to trade, its buying/selling power could inflate/deflate prices. This creates a coordination problem—the strategy that works when you’re alone stops working when everyone adopts it.
Regulatory Uncertainty: Current use of LLMs in traditional finance is limited to “risk-free tasks with heavy human assistance, such as text summarization.” A Gilbert + Tobin report suggests broader adoption may come in the next two years, but heavily regulated environments remain cautious.
The Systemic Risk Question
The most unsettling implication: what happens when autonomous AI trading becomes widespread?
If DeepSeek’s strategy works, others will copy it. But markets are zero-sum in the short term—someone’s profit is someone else’s loss. When multiple AI systems adopt similar strategies, they might:
- Compete away profits through front-running
- Create crowding in popular trades
- Trigger synchronized buying/selling that overwhelms liquidity
- Generate feedback loops that destabilize markets
Financial regulators are watching closely but have little framework for managing AI trading risk. The traditional approach—auditing algorithms, requiring kill switches, stress testing—assumes human oversight. Fully autonomous agents challenge these assumptions.
What Comes Next
Alpha Arena Season 1 ends November 3, 2025. Rankings remain volatile and could shift dramatically in the final days—cryptocurrency markets are notoriously unpredictable, and even the best-performing models have experienced sharp reversals.
Season 2 and Beyond:
Nof1 plans to continue the experiment with:
- Additional models (potentially Claude Opus 4, GPT-5.5, newer Chinese models)
- Longer trading periods (to test sustained performance)
- Different asset classes (equities, forex, commodities)
- More complex scenarios (bear markets, high-volatility regimes)
Research Directions:
The academic community is racing to understand these results. Key questions:
- Reproducibility: Will DeepSeek and Qwen continue to dominate in different market conditions?
- Generalization: Do these models trade other assets as well as crypto?
- Mechanism: What specifically about their architecture/training enables better trading?
- Safety: Can we build AI trading systems with reliable risk controls?
Industry Adoption:
Wall Street remains cautious but curious. Andrew Ng, prominent AI researcher, suggests that “using agentic workflows with GPT-4 is akin to having early access to GPT-5”—implying that well-designed AI agents can provide competitive edge in trading.
Quantitative hedge funds and prop trading firms are already experimenting with:
- LLM-enhanced signal generation
- Multi-agent research teams (mimicking TradingAgents)
- Hybrid LLM+RL systems
- AI-powered risk management
But full autonomy, like Alpha Arena, remains rare. Most implementations keep humans in the loop for final decisions—at least for now.
The Verdict: AI Trading Is Real, But Not Ready
Alpha Arena proves that large language models can trade autonomously and, in some cases, generate significant returns. DeepSeek and Qwen’s performance demonstrates that AI trading isn’t just theoretical—it can work in live markets with real money.
But the catastrophic failures of GPT-5 and Gemini reveal the risks. These are some of the world’s most advanced AI systems, developed by companies with billions in resources. Yet they lost 30-60% of their capital in days.
The lesson: AI trading capability exists, but reliability doesn’t. We’re in an experimental phase where the best models can outperform traditional strategies, but predicting which model will succeed remains difficult.
For researchers, Alpha Arena provides invaluable data on AI decision-making under pressure. For traders, it’s a fascinating experiment but not yet a trusted tool. For the financial system, it’s an early warning—autonomous AI trading is coming, and we’re not ready for the implications.
One thing is certain: the models are learning. Every trade, every loss, every market condition feeds future training. The question isn’t whether AI will eventually dominate trading—it’s how soon, and whether we can manage the transition without breaking the markets in the process.
Alpha Arena leaderboard is live at nof1.ai/leaderboard. Season 1 concludes November 3, 2025. All trades, positions, and model reasoning are publicly accessible.
TradingAgents framework is open-source at github.com/TauricResearch/TradingAgents.
My Amazon Picks
As an Amazon Associate I earn from qualifying purchases.

5TH WHEEL Electric Bike for Adults
1000W peak power, a removable 468Wh battery, and trail-ready suspension make this commuter-ready e-bike a capable all-terrain ride.
- Brushless hub motor surges to 37 km/h with a 7-speed drivetrain to keep pace on climbs.
- Removable UL 2849-certified battery delivers up to 88 km with PAS and charges on or off the frame.
Join the discussion
Thoughts, critiques, and curiosities are all welcome.